什么是 ElasticSearch
Elasticsearch 是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理
大规模数据。$\color{red}{ElasticSearch 是一个基于 Lucene 的搜索服务器。}$
它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口。Elasticsearch 是用 Java 开发的,并作为 Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
$\color{green}{设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。}$
ElasticSearch 特点
- 可以作为一个大型分布式集群(数百台服务器)技术,处理 PB 级数据,服务大公司;也可以运行在单机上
- 将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的 ES;
- 开箱即用的,部署简单
- 全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理
Solr 与 Elasticsearch 对比
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持 json 文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第
三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
ElasticSearch 部署与启动
下载 ElasticSearch 5.6.8 版本
https://www.elastic.co/downloads/past-releases/elasticsearch-5-6-8
在命令提示符下,进入 ElasticSearch 安装目录下的 bin 目录,执行命令
即可启动。
我们打开浏览器,在地址栏输入 http://127.0.0.1:9200 即可看到输出结果
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"name" : "uV2glMR",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "RdV7UTQZT1‐Jnka9dDPsFg",
"version" : {
"number" : "5.6.8",
"build_hash" : "688ecce",
"build_date" : "2018‐02‐16T16:46:30.010Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
|
ElasticSearch 体系结构
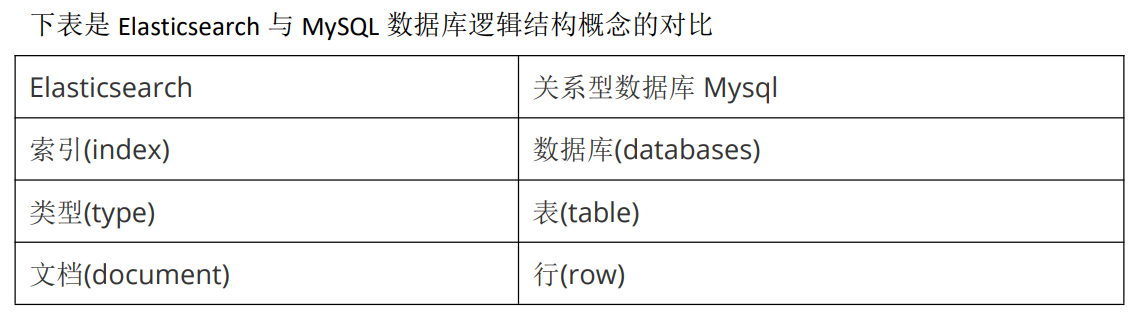
Postman 调用 REST API
例如我们要创建一个叫 articleindex 的索引 ,就以 put 方式提交
http://127.0.0.1:9200/articleindex/
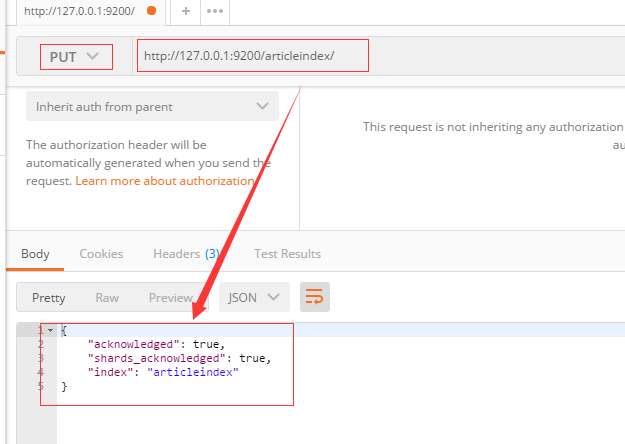
新建文档
以 post 方式提交 http://127.0.0.1:9200/articleindex/article
body:
1
2
3
4
|
{
"title":"SpringBoot2.0",
"content":"发布啦"
}
|
返回结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"_index": "articleindex",
"_type": "article",
"_id": "AWPKsdh0FdLZnId5S_F9",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
|
id 是由系统自动生成的。 为了方便之后的演示,我们再次录入几条测试数据。
查询全部文档
查询某索引某类型的全部数据,以 get 方式请求
http://127.0.0.1:9200/articleindex/article/_search
返回结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "articleindex",
"_type": "article",
"_id": "AWPKrI4pFdLZnId5S_F7",
"_score": 1,
"_source": {
"title": "SpringBoot2.0",
"content": "发布啦"
}
},
{
"_index": "articleindex",
"_type": "article",
"_id": "AWPKsdh0FdLZnId5S_F9",
"_score": 1,
"_source": {
"title": "elasticsearch 入门",
"content": "零基础入门"
}
}
]
}
}
|
修改文档
以 put 形式提交以下地址
http://127.0.0.1:9200/articleindex/article/AWPKrI4pFdLZnId5S_F7
body:
1
2
3
4
|
{
"title":"SpringBoot2.0 正式版",
"content":"发布了吗"
}
|
返回结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"_index": "articleindex",
"_type": "article",
"_id": "AWPKsdh0FdLZnId5S_F9",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
|
如果我们在地址中的 ID 不存在,则会创建新文档
以 put 形式提交以下地址:
1
|
http://127.0.0.1:9200/articleindex/article/
|
body:
1
2
3
4
|
{
"title":"十次方课程好给力",
"content":"知识点很多"
}
|
返回结果
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"_index": "articleindex",
"_type": "article",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
|
再次查询,看是否有新增的这条文档
按照 ID 查询文档
GET 方式请求
1
|
http://127.0.0.1:9200/articleindex/article/1
|
基本匹配查询
根据某列进行查询 get 方式提交下列地址:
1
|
http://127.0.0.1:9200/articleindex/article/_search?q=title:你好
|
根据某列进行查询 get 方式提交下列地址:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 2.0649285,
"hits": [
{
"_index": "articleindex",
"_type": "article",
"_id": "1",
"_score": 2.0649285,
"_source": {
"title": "你好",
"content": "知识点很多"
}
}
]
}
}
|
模糊查询
我们可以用*代表任意字符:
1
|
http://127.0.0.1:9200/articleindex/article/_search?q=title:*s*
|
删除文档
根据 ID 删除文档,删除 ID 为 1 的文档 DELETE 方式提交
1
|
http://127.0.0.1:9200/articleindex/article/1
|
返回结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"found": true,
"_index": "articleindex",
"_type": "article",
"_id": "1",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
|
再次查看全部是否还存在此记录
Head 插件的安装与使用
Head 插件安装
如果都是通过 rest 请求的方式使用 Elasticsearch,未免太过麻烦,而且也不够人性化。我们
一般都会使用图形化界面来实现 Elasticsearch 的日常管理,最常用的就是 Head 插件。
步骤 1:
下载 head 插件:https://github.com/mobz/elasticsearch-head
步骤 2:
解压到任意目录,但是要和 elasticsearch 的安装目录区别开。
步骤 3:
安装 node js ,安装 cnpm
1
|
npm install ‐g cnpm ‐‐registry=https://registry.npm.taobao.org
|
步骤 4:
将 grunt 安装为全局命令 。Grunt 是基于 Node.js 的项目构建工具。它可以自动运行你所设定的任务
1
|
npm install ‐g grunt‐cli
|
步骤 5:安装依赖
步骤 6:
进入 head 目录启动 head,在命令提示符下输入命令
步骤 7:
打开浏览器,输入 http://localhost:9100
步骤 8:
点击连接按钮没有任何相应,按 F12 发现有如下错误
1
|
No 'Access-Control-Allow-Origin' header is present on the requested resource
|
这个错误是由于 elasticsearch 默认不允许跨域调用,而 elasticsearch-head 是属于前端工程,所以报错。我们这时需要修改 elasticsearch 的配置,让其允许跨域访问。
修改 elasticsearch 配置文件:elasticsearch.yml,增加以下两句命令:
1
2
|
http.cors.enabled: true
http.cors.allow-origin: "*" 此步为允许 elasticsearch 跨越访问 点击连接即可看到相关信息
|
IK 分词器
我们在浏览器地址栏输入
1
|
http://127.0.0.1:9200/_analyze?analyzer=chinese&pretty=true&text=我是程序员,
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "程",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "序",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
|
默认的中文分词是将每个字看成一个词,这显然是不符合要求的,所以我们需要安装中文分
词器来解决这个问题。
IK 分词是一款国人开发的相对简单的中文分词器。虽然开发者自 2012 年之后就不在维护了,
但在工程应用中 IK 算是比较流行的一款
IK 分词器安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
- 先将其解压,将解压后的 elasticsearch 文件夹重命名文件夹为 ik
- 将 ik 文件夹拷贝到 elasticsearch/plugins 目录下。
- 重新启动,即可加载 IK 分词
IK 分词器测试
IK 提供了两个分词算法 ik_smart 和 ik_max_word其中 ik_smart 为最少切分,ik_max_word 为最细粒度划分
我们分别来试一下
- 最小切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
输出的结果为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
}
]
}
|
- 最细切分:在浏览器地址栏输入地址
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员
输出的结果为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "程序员",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "程序",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "员",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 4
}
]
}
|
自定义词库
我们现在测试"万众创新”,浏览器的测试效果如下:
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=万众创新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
{
"tokens": [
{
"token": "万众",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "创新",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}
]
}
|
默认的分词并没有识别“万众创新”是一个词。如果我们想让系统识别“万众创新”是一个词,需要编辑自定义词库。
步骤:
- 进入 elasticsearch/plugins/ik/config 目录
- 新建一个 my.dic 文件,编辑内容:
万众创新
修改 IKAnalyzer.cfg.xml(在 ik/config 目录下)
1
2
3
4
5
6
7
|
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!‐‐用户可以在这里配置自己的扩展字典 ‐‐>
<entry key="ext_dict">my.dic</entry>
<!‐‐用户可以在这里配置自己的扩展停止词字典‐‐>
<entry key="ext_stopwords"></entry>
</properties>
|
重新启动 elasticsearch,通过浏览器测试分词效果
1
2
3
4
5
6
7
8
9
10
11
|
{
"tokens": [
{
"token": "万众创新",
"start_offset": 0,
"end_offset": 4,
"type": "CN_WORD",
"position": 0
}
]
}
|
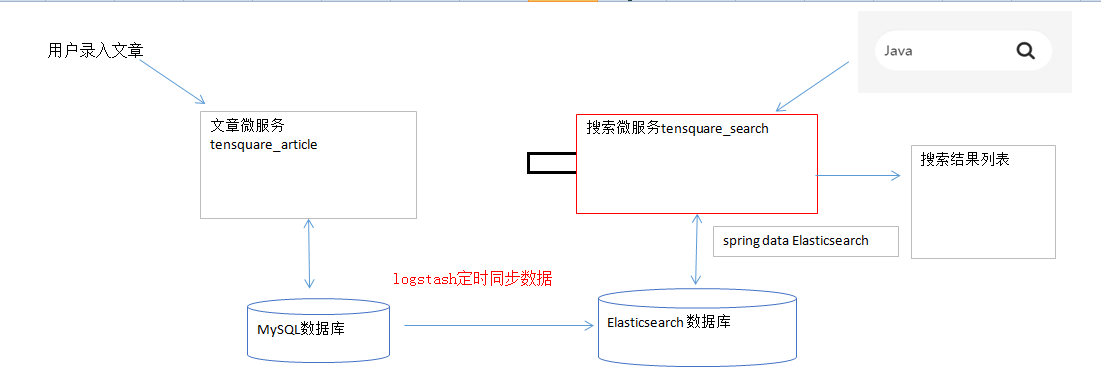
ElasticSearch 与 MySQL 数据同步
什么 logstash
Logstash 是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,
并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
logstash 安装与测试
解压,进入 bin 目录
1
2
3
4
5
6
7
8
|
logstash -e 'input { stdin {} } output { stdout {} } '
stdin,表示输入流,指从键盘输入
stdout,表示输出流,指从显示器输出
命令行参数: -e 执行
--config 或 -f 配置文件,后跟参数类型可以是一个字符串的配置或全路径文件名或全路径
路径(如:/etc/logstash.d/,logstash 会自动读取/etc/logstash.d/目录下所有*.conf 的文
本文件,然后在自己内存里拼接成一个完整的大配置文件再去执行)
|
MySQL 数据导入 ElasticSearch
- 在 logstash-5.6.8 安装目录下创建文件夹 mysqletc (名称随意)
- 文件夹下创建 mysql.conf (名称随意) ,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
input {
jdbc {
# mysql jdbc connection string to our backup databse
jdbc_connection_string => "jdbc:mysql://192.168.2.2:3306/tensquare_article?characterEncoding=UTF8"
# the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => "123456"
# the path to our downloaded jdbc driver
jdbc_driver_library => "F:/software_app/ten/elasticsearch-5.6.8/logstash-5.6.8/logstash-5.6.8/mysqletc/mysql-connector-java-5.1.46.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#以下对应着要执行的sql的绝对路径。
#statement_filepath => ""
statement => "select id,title,content from tb_article"
#定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新(测试结果,不同的话请留言指出)
schedule => "* * * * *"
}
}
output {
elasticsearch {
#ESIP地址与端口
hosts => "127.0.0.1:9200"
#ES索引名称(自己定义的)
index => "tensquare"
#自增ID编号
document_id => "%{id}"
document_type => "article"
}
stdout {
#以JSON格式输出
codec => json_lines
}
}
|
- 将 mysql 驱动包 mysql-connector-java-5.1.46.jar 拷贝至 D:/logstash- 5.6.8/mysqletc/ 下 。D:/logstash-5.6.8 是你的安装目录
- bin目录下cmd命令行下执行
1
|
logstash ‐f ../mysqletc/mysql.conf
|
代码实现
entity
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
|
/**
* 实体类
* @author Administrator
*
*/
@Document(type = "article",indexName = "tensquare")
public class Article implements Serializable{
@Id // 映射_id
private String id;//ID
private String columnid;//专栏ID
private String userid;//用户ID
private String title;//标题
private String content;//文章正文
private String image;//文章封面
private java.util.Date createtime;//发表日期
private java.util.Date updatetime;//修改日期
private String ispublic;//是否公开
private String istop;//是否置顶
private Integer visits;//浏览量
private Integer thumbup;//点赞数
private Integer comment;//评论数
private String state;//审核状态
private String channelid;//所属频道
private String url;//URL
private String type;//类型
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getColumnid() {
return columnid;
}
public void setColumnid(String columnid) {
this.columnid = columnid;
}
public String getUserid() {
return userid;
}
public void setUserid(String userid) {
this.userid = userid;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getImage() {
return image;
}
public void setImage(String image) {
this.image = image;
}
public java.util.Date getCreatetime() {
return createtime;
}
public void setCreatetime(java.util.Date createtime) {
this.createtime = createtime;
}
public java.util.Date getUpdatetime() {
return updatetime;
}
public void setUpdatetime(java.util.Date updatetime) {
this.updatetime = updatetime;
}
public String getIspublic() {
return ispublic;
}
public void setIspublic(String ispublic) {
this.ispublic = ispublic;
}
public String getIstop() {
return istop;
}
public void setIstop(String istop) {
this.istop = istop;
}
public Integer getVisits() {
return visits;
}
public void setVisits(Integer visits) {
this.visits = visits;
}
public Integer getThumbup() {
return thumbup;
}
public void setThumbup(Integer thumbup) {
this.thumbup = thumbup;
}
public Integer getComment() {
return comment;
}
public void setComment(Integer comment) {
this.comment = comment;
}
public String getState() {
return state;
}
public void setState(String state) {
this.state = state;
}
public String getChannelid() {
return channelid;
}
public void setChannelid(String channelid) {
this.channelid = channelid;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
}
|
dao
1
2
3
4
5
6
7
8
9
10
11
|
/**
* 文章dao
*/
public interface ArticleDao extends ElasticsearchRepository<Article,String> {
/**
* 文章查询
*/
public Page<Article> findByTitleOrContentLike(String title, String content, Pageable pageable);
}
|
service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
/**
* 文章service
*/
@Service
public class ArticleService {
@Autowired
private ArticleDao articleDao;
/**
* 文章搜素
*/
public Page<Article> search(String keyword, int page, int size){
return articleDao.findByTitleOrContentLike(keyword,keyword, PageRequest.of(page-1,size));
}
}
|
Controller
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
/**
* 文章controller
*/
@RestController
@RequestMapping("/article")
@CrossOrigin
public class ArticleController {
@Autowired
private ArticleService articleService;
/**
* 文章搜索
*/
@RequestMapping(value = "/search/{keyword}/{page}/{size}",method = RequestMethod.GET)
public Result search(@PathVariable String keyword,@PathVariable int page,@PathVariable int size){
Page<Article> pageData = articleService.search(keyword,page,size);
return new Result(true, StatusCode.OK,"搜索成功",new PageResult<>(pageData.getTotalElements(),pageData.getContent()));
}
}
|
application.yml
1
2
3
4
5
6
7
8
|
server:
port: 9007
spring:
application:
name: search
data:
elasticsearch:
cluster-nodes: 192.168.2.2:9300
|
流程图
ElasticSearch Docker 环境下安装
下载镜像
1
|
docker pull elasticsearch:5.6.8
|
创建容器
1
|
docker run ‐di ‐‐name=tensquare_elasticsearch ‐p 9200:9200 ‐p 9300:9300 elasticsearch:5.6.8
|
浏览器输入地址: http://192.168.184.134:9200/
即可看到如下信息
1
2
3
4
5
6
7
8
9
10
11
12
13
|
{
"name" : "WmBn0H‐",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "2g‐VVbm9Rty7J4sksZNJEg",
"version" : {
"number" : "5.6.8",
"build_hash" : "688ecce",
"build_date" : "2018‐11‐2T16:46:30.010Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
|
我们修改 demo 的 application.yml
spring:
data:
elasticsearch:
cluster‐nodes: 192.168.2.2:9300
##运行测试程序,发现会报如下错误
1
2
3
4
5
6
7
8
9
10
11
12
13
|
NoNodeAvailableException[None of the configured nodes are available:
[{#transport#‐1}{exvgJLR‐RlCNMJy‐hzKtnA}{192.168.2.2}
{192.168.2.2:9300}]
]
at
org.elasticsearch.client.transport.TransportClientNodesService.ensureNodes
AreAvailable(TransportClientNodesService.java:347)
at
org.elasticsearch.client.transport.TransportClientNodesService.execute(Tra
nsportClientNodesService.java:245)
at
org.elasticsearch.client.transport.TransportProxyClient.execute(TransportP
roxyClient.java:59)
|
这是因为 elasticsearch 从 5 版本以后默认不开启远程连接,需要修改配置文件
我们进入容器
1
|
docker exec ‐it myElasticsearch /bin/bash
|
此时,我们看到 elasticsearch 所在的目录为/usr/share/elasticsearch ,进入 config 看到了配置文件elasticsearch.yml
我们通过 vi 命令编辑此文件,尴尬的是容器并没有 vi 命令 ,咋办?我们需要以文件挂载
的方式创建容器才行,这样我们就可以通过修改宿主机中的某个文件来实现对容器内配置文
件的修改
拷贝配置文件到宿主机
首先退出容器,然后执行命令:
1
|
docker cp myElasticsearch:/usr/share/elasticsearch/config/elasticsearch.yml /usr/share/elasticsearch.yml
|
停止和删除原来创建的容器
1
2
|
docker stop myElasticsearch
docker rm myElasticsearch
|
重新执行创建容器命令
1
|
docker run ‐di ‐‐name=myElasticsearch ‐p 9200:9200 ‐p 9300:9300 ‐v /usr/share/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch:5.6.8
|
修改/usr/share/elasticsearch.yml 将 transport.host: 0.0.0.0 前的#去掉后
保存文件退出。其作用是允许任何 ip 地址访问 elasticsearch .开发测试阶段可以这么做,
生产环境下指定具体的 IP
重启启动
1
|
docker restart myElasticsearch
|
重启后发现重启启动失败了,这时什么原因呢?这与我们刚才修改的配置有关,因为
elasticsearch 在启动的时候会进行一些检查,比如最多打开的文件的个数以及虚拟内存区
域数量等等,如果你放开了此配置,意味着需要打开更多的文件以及虚拟内存,所以我们还
需要系统调优。
系统调优
我们一共需要修改两处
修改/etc/security/limits.conf ,追加内容
1
2
|
* soft nofile 65536
* hard nofile 65536
|
nofile 是单个进程允许打开的最大文件个数 soft nofile 是软限制 hard nofile 是硬限制
修改/etc/sysctl.conf,追加内容
1
|
vm.max_map_count=655360
|
限制一个进程可以拥有的 VMA(虚拟内存区域)的数量
执行下面命令 修改内核参数马上生效
重新启动虚拟机,再次启动容器,发现已经可以启动并远程访问
IK 分词器安装
快捷键 alt+p 进入 sftp , 将 ik 文件夹上传至宿主机
1
|
sftp> put -r d:\setup\ik
|
在宿主机中将 ik 文件夹拷贝到容器内 /usr/share/elasticsearch/plugins 目录下。
1
|
docker cp ik myElasticsearch:/usr/share/elasticsearch/plugins/
|
重新启动,即可加载 IK 分词器
1
|
docker restart myElasticsearch
|
Head 插件安装
修改/usr/share/elasticsearch.yml ,添加允许跨域配置
1
2
|
http.cors.enabled: true
http.cors.allow‐origin: "*"
|
重新启动 elasticseach 容器
下载 head 镜像
1
|
docker pull mobz/elasticsearch-head:5
|
创建 head 容器
1
|
docker run -di --name=myhead -p 9100:9100 mobz/elasticsearch-head:5
|
logstash 安装
下载 logstash 镜像
创建 logstash 目录
1
|
mkdir /usr/local/logstash
|
在 logstash 目录下建立 Dockerfile 文件,内容如下:
1
2
3
4
5
|
FROM logstash
CMD [“-f”,”/usr/local/logstash/mysql.conf”]
FROM logstash:意思是镜像构建在 logstash 基础之上
CMD [“-f”,”/usr/local/logstash/mysql.conf”]:代表在 docker run 运行镜像,容器内
部启动过程中,添加参数 -f /usr/local/logstash/mysql.conf。
|
构建新的 logstash 镜像
1
|
docker build -t logstash_new . 构建后查询 logstash_new 镜像是否构建成功。
|
以目录挂载形式启动新的 logstash 镜像
1
|
docker run -di --name=logstash -v /usr/local/logstash:/usr/local/logstash
|
logstash_new
把 之 前 在 window 的 mysql.conf 和 mysql 驱 动 文 件 上 传 到 宿 主 机 的
/usr/local/logstash 目录下面
修改 mysql.conf 内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
input {
jdbc {
# mysql jdbc connection string to our backup databse
jdbc_connection_string =>
"jdbc:mysql://192.168.22.22:3306/article?characterEncoding=UTF8" # the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => "123456" # the path to our downloaded jdbc driver
jdbc_driver_library => "/usr/local/logstash/mysql-connector-java-5.1.46.jar" # the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000" #以下对应着要执行的 sql 的绝对路径。
#statement_filepath => ""
statement => "select id,title,content from tb_article" #定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分
钟都更新(测试结果,不同的话请留言指出)
schedule => "* * * * *"
}
}
output {
elasticsearch {
#ESIP 地址与端口
hosts => "192.168.2.2:9200" #ES 索引名称(自己定义的)
index => "articleId" #自增 ID 编号
document_id => "%{id}" document_type => "article"
}
stdout {
#以 JSON 格式输出
codec => json_lines
}
}
|
重启 logstash 容器
1
|
docker restart logstash
|
查看 logstash 容器日志,看是否 1 分钟同步一次数据到 elasticsearch
1
|
docker logs -f --tail=30 logstash
|