谈谈网络爬虫
什么网络爬虫
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人 力进行信息采集,不仅低效繁琐,搜集的成本也会提高。如何自动高效地获取互联网中我们 感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而生的。 网络爬虫(Web crawler)也叫做网络机器人,可以代替人们自动地在互联网中进行数据 信息的采集与整理。它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,可 以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。 从功能上来讲,$\color{red}{爬虫一般分为数据采集,处理,储存三个部分。}$爬虫从一个或若干初始 网页的 URL 开始,获得初始网页上的 URL,在抓取网页的过程中,不断从当前页面上抽取新 的 URL 放入队列,直到满足系统的一定停止条件。
网络爬虫可以做什么
我们初步认识了网络爬虫,网络爬虫具体可以做什么呢?
- 可以实现搜索引擎
- 大数据时代,可以让我们获取更多的数据源。
- 快速填充测试和运营数据
- 为人工智能提供训练数据集
网络爬虫常见的技术(Java)
底层实现 HttpClient+Jsoup
HttpClient 是 Apache Jakarta Common 下的子项目,用来提供高效的、最新的、功能丰富的
支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
HttpClient 已经应用在很多的项目中,比如 Apache Jakarta 上很著名的另外两个开源项目
Cactus 和 HTMLUnit 都使用了 HttpClient。更多信息请关注 http://hc.apache.org/
jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提
供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数
据。
开源框架 WebMagic
webmagic 是一个开源的 Java 爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑
功能的开发。webmagic 的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫
开发的材料。
webmagic 的主要特色:
完全模块化的设计,强大的可扩展性。
核心简单但是涵盖爬虫的全部流程,灵活而强大,也是学习爬虫入门的好材料。
提供丰富的抽取页面 API。
无配置,但是可通过 POJO+注解形式实现一个爬虫。
支持多线程。
支持分布式。
支持爬取 js 动态渲染的页面。
无框架依赖,可以灵活的嵌入到项目中去。
爬虫框架 WebMagic
架构解析
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个精简的、模块
化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。扩展部分(webmagic-extension)
提供一些便捷的功能,例如注解模式编写爬虫等。同时内置了一些常用的组件,便于爬虫开
发。
WebMagic 的设计目标是尽量的模块化,并体现爬虫的功能特点。这部分提供非常简单、
灵活的 API,在基本不改变开发模式的情况下,编写一个爬虫。
WebMagic 的结构分为 Downloader、PageProcessor、Scheduler、Pipeline 四大组件,并由
Spider 将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化
等功能。而 Spider 则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以
认为 Spider 是一个大的容器,它也是 WebMagic 逻辑的核心。
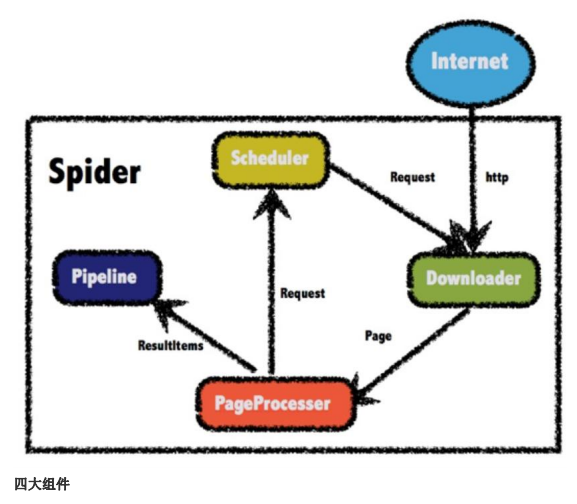
四大组件
Downloader
Downloader 负责从互联网上下载页面,以便后续处理。WebMagic 默认使用了 ApacheHttpClient 作为下载工具。
PageProcessor
PageProcessor 负责解析页面,抽取有用信息,以及发现新的链接。WebMagic 使用 Jsoup 作为 HTML 解析工具,并基于其开发了解析 XPath 的工具 Xsoup。 在这四个组件中,PageProcessor 对于每个站点每个页面都不一样,是需要使用者定制的 部分。
Scheduler
Scheduler 负责管理待抓取的 URL,以及一些去重的工作。WebMagic 默认提供了 JDK 的 内存队列来管理 URL,并用集合来进行去重。也支持使用 Redis 进行分布式管理。
Pipeline
Pipeline 负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic 默认提供 了“输出到控制台”和“保存到文件”两种结果处理方案 。
爬取页面全部内容
导入依赖
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
编写类实现网页内容的爬取
|
|
- 原文作者:Jeremy Sze
- 原文链接:https://jeremy95-sze.github.io/post/%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。